
ECS(Fargate)でDBテスト用の大容量データ(CSV)を生成してみた

こんにちは、ゲームソリューション部のsoraです。
今回は、ECS(Fargate)でDBテスト用の大容量データ(CSV)を生成してみたことについて書いていきます。
やりたいこと
DBのテストをするときに、インポートして使える大きなサイズのCSVファイルがほしくなることがあったため、そのファイルを生成するためのツールを作成します。
ファイルサイズを指定して、以下のようなファイルを生成します。
商品ID,商品名,カテゴリ,価格,在庫数,説明,発売日
・・・
今回ECSで実行していますが、AWS Batchでも良かったかなと思いました。
ソースコード
コードは以下です。
商品IDをプライマリキーとするため、重複が起こらないようにチェックを入れています。(オートインクリメントではなく、ランダムにしています。)
重複チェックについて、5回連続で重複する値が生成された場合はエラー終了するようにしていますが、無限ループにしても良いと思います。
ファイルサイズとバッファサイズはECSのタスク定義で環境変数として指定し、タスク定義を更新することで変更できるようにしています。
ファイルサイズ的にECSを使うほどでもない場合は、S3にアップロードする箇所と環境変数を使う場所を修正すれば、ローカルでも使用できます。
import csv
import random
import string
import datetime
import os
# ローカルで実行する場合は不要
import boto3
def generate_random_string(length):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def generate_random_date(start_date, end_date):
return start_date + datetime.timedelta(
days=random.randint(0, (end_date - start_date).days))
# ファイルサイズを指定(ローカルで使用する場合は書き換える)
target_file_size_mb = int(os.getenv('TARGET_FILE_SIZE_MB', '10'))
target_file_size_bytes = target_file_size_mb * 1000 * 1000
buffer_size_bytes = int(os.getenv('BUFFER_SIZE_BYTES', '100'))
# CSVファイルのフィールド名
fieldnames = ['商品ID', '商品名', 'カテゴリ', '価格', '在庫数', '説明', '発売日']
# サンプルデータの生成
categories = ['Electronics', 'Clothing', 'Books', 'Home', 'Toys']
start_date = datetime.date(2000, 1, 1)
end_date = datetime.date(2023, 12, 31)
# 生成された商品IDを保持するセット
# set()は重複する要素を持たない特性がある
# 重複チェックが簡単にできる
generated_product_ids = set()
# S3バケットとキーを指定
s3_bucket = 'sora-anything-test'
s3_key = 'product_data.csv'
# ファイルを開く
file_path = 'product_data.csv'
with open(file_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
while file.tell() < (target_file_size_bytes - buffer_size_bytes):
# 重複しない商品IDを生成(5回重複したらエラー終了する)
duplicate_attempts = 0
while duplicate_attempts < 5:
product_id = generate_random_string(20)
if product_id not in generated_product_ids:
generated_product_ids.add(product_id)
break
duplicate_attempts += 1
else:
print("商品IDの重複が5回発生しました。生成を終了します。")
break
product_name = generate_random_string(15)
category = random.choice(categories)
price = round(random.uniform(10.0, 1000.0), 2)
stock = random.randint(0, 1000)
description_length = random.randint(20, 100)
description = generate_random_string(description_length)
release_date = generate_random_date(start_date, end_date).strftime('%Y-%m-%d')
row = {
'商品ID': product_id,
'商品名': product_name,
'カテゴリ': category,
'価格': price,
'在庫数': stock,
'説明': description,
'発売日': release_date
}
# 行のサイズを確認
row_size = sum(len(str(value)) for value in row.values()) + len(fieldnames) - 1 + 2 # カンマと改行のサイズ
if file.tell() + row_size > target_file_size_bytes:
break
writer.writerow(row)
print("CSVファイルが生成されました: product_data.csv")
# S3にアップロード(ローカルで実行する場合は不要)
s3_client = boto3.client('s3')
s3_client.upload_file(file_path, s3_bucket, s3_key)
print(f"CSVファイルがS3にアップロードされました: s3://{s3_bucket}/{s3_key}")
boto3
FROM python:3.12-slim
WORKDIR /app
COPY src /app
RUN pip3 install -r /app/requirements.txt
CMD ["python3", "/app/main.py"]
AWSリソースの作成・設定
情報は多く落ちているため、簡潔に記載します。
エンドポイントの作成
今回はECS(Fargate)をプライベートサブネットで使用するため、以下エンドポイントを作成します。
ログは出力しないため、CloudWatch用のエンドポイントは含んでいません。
com.amazonaws.ap-northeast-1.s3(Gateway)com.amazonaws.ap-northeast-1.ecr.dkrcom.amazonaws.ap-northeast-1.ecr.api
ECSのタスク定義
ECRへイメージをプッシュした後、ECSのタスク定義を作成します。
ECSタスクロールにはECRへのアクセス権限、ECSタスク実行ロールにはS3へのアクセス権限を付与しておきます。
※私はタスクロールの設定が漏れていて無駄に時間を取られました。
また環境変数として、TARGET_FILE_SIZE_MBとBUFFER_SIZE_BYTESを追加します。
(環境変数はすべて文字列になるため、Pythonのコード内でintに変換して使用します。)
実行
ECSにてタスクを実行すると、S3にCSVファイルが生成されていました。
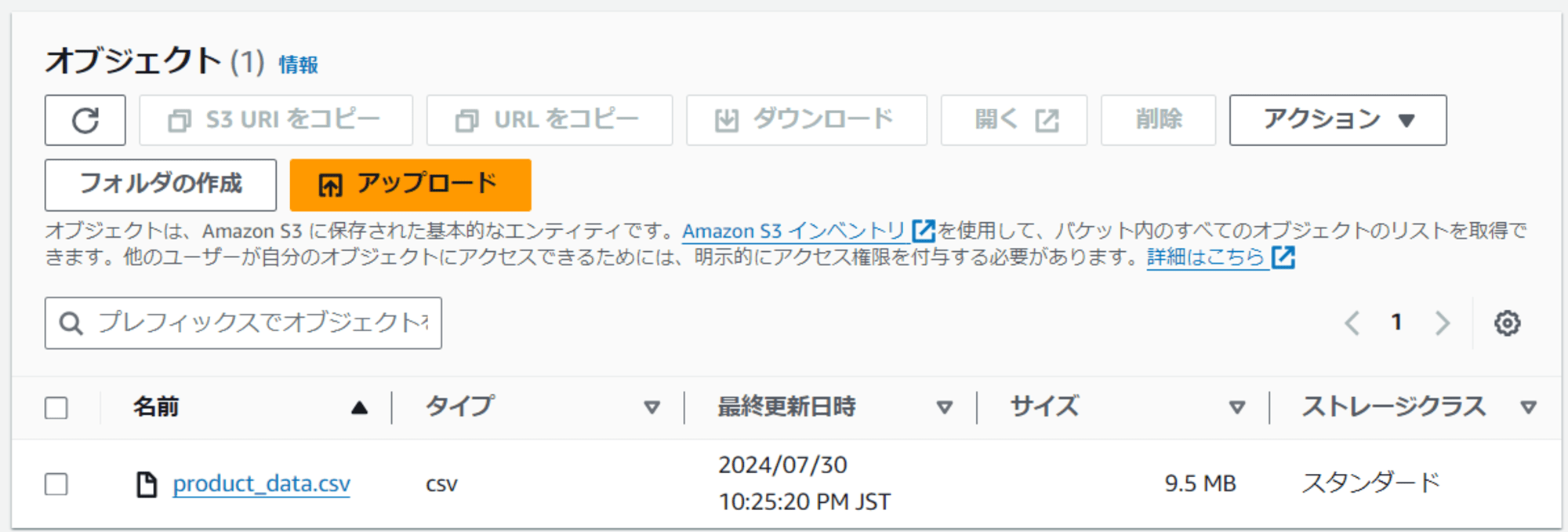
以下はファイルの中身の抜粋です。
商品ID,商品名,カテゴリ,価格,在庫数,説明,発売日
BqAIJZ6mwGvSYKtAwWbw,Q8bXMTWg6B5dNeR,Clothing,139.39,374,EyNMkhnNiewB5TlDT4y30gf0Qc5Dp8V3mj3mRCDgoeVYVyjLPlyg0lHYnAyQojM,2005-02-07
ZhGgHKnuBR4dVUBOvdgT,jqI3zB8nmlBpEBE,Home,683.66,156,dW4GLWzoL4RWx5dXgJXZuXGBGrwpQZXNchGijxE2mnPnoLMHb96ueF71X,2017-11-08
7czlCOeNLYKTGFsTkclL,huAMopGnZh21LWf,Electronics,915.74,932,sbuZpZOsqDXVF8XP1jS9eMQoJxQ,2003-08-04
・・・
最後に
今回は、ECS(Fargate)でDBテスト用の大容量データ(CSV)を生成してみたことを記事にしました。
どなたかの参考になると幸いです。





